

Docker搭建rocketmq环境
Docker搭建rocketmq环境搜索rocketmq镜像1docker search rocketmq
结果如下:我这里选择了apache/rocketmq 镜像
1docker pull apache/rocketmq
创建namesrv容器创建本地目录,用来将容器的日志挂载到本地,方便日志查看
1mkdir -p /Users/atomic/docker/rocketmq/namesrv/logs
创建并启动namesrv容器
1234567docker run -d -p 9876:9876 \ -v /Users/atomic/docker/rocketmq/namesrv/logs:/home/rocketmq/logs \ --name mqnamesrv \ -e "MAX_POSSIBLE_HEAP=100000000" \ -e "JAVA_OPTS=-D ...

Mac宿主机访问Docker容器网络
在mac上实践在docker中搭建rocketmq环境,发现宿主程序发送MQ消息连接失败,排查原因是broker注册到namesrv上的IP地址是docker容器的地址,而宿主机不能直接访问。后来更换了network host方式依然不行,经查询资料发现mac下的docker部署方式是将docker服务端部署在一台虚拟机里面,导致host方式通信失效。
解决方法先安装Mac端的服务mac-docker-connector12$ brew tap wenjunxiao/brew$ brew install docker-connector
首次配置通过以下命令把所有Docker所有bridge子网放入配置文件,后续的增减可以参考后面的详细配置
1$ docker network ls --filter driver=bridge --format "{{.ID}}" | xargs docker network inspect --format "route {{range .IPAM.Conf ...

git的使用技巧
简介git的各种使用技巧(持续更新)
使用技巧git的.ignore不生效原因:在项目开发过程中个,一般都会添加 .gitignore 文件,规则很简单,但有时会发现,规则不生效。原因是 .gitignore 只能忽略那些原来没有被track的文件,如果某些文件已经被纳入了版本管理中,则修改.gitignore是无效的。那么解决方法就是先把本地缓存删除(改变成未track状态),然后再提交。
123git rm -r --cached .git add .git commit -m 'update .gitignore'
参考
https://git-scm.com/
Java之并发一百问
Java之并发一百问Q1:线程越多程序是否就运行得越快?答:并发编程的目的是为了让程序运行得更快,但是并不是启动得线程越多就能让程序最大限度地并发执行。在并发编程时,如果希望通过多线程执行任务让程序运行得更快会面临很多挑战,比如上下文切换的问题、死锁的问题,以及受限于硬件和软件的资源限制问题。
Q2:多线程并发是怎么实现的,必须要用多核处理器实现吗?答:即使是单核处理器也支持多线程执行代码,CPU通过给每个线程分配CPU时间片来实现这个机制。时间片是CPU分配给各个线程的时间,因为时间片非常短(一般是几十毫秒),所以CPU通过不停地切换线程执行,让我们感觉多个线程是同时执行的。- Q3:什么是上下文切换?答:CPU是通过时间片分配算法来循环执行任务,当前任务执行一个时间片后会切换到下一个任务。但是在切换前会保存上一个任务的状态,以便下次再切换回这个任务时可以再加载这个任务的状态。所以任务从保存到再加载的过程就是一次上下文切换。
Q4:如何减少上下文切换?答:①无锁并发编程:多线程竞争锁时会引起上下文切换,所以多线程处理数据时,可以通过一些方法来避免使用锁,例如将数据的id按照hash算 ...
Mac绿色安装redis
centos7.4绿色安装redis下载安装redis服务1234$ wget https://download.redis.io/releases/redis-6.0.10.tar.gz$ tar xzf redis-6.0.10.tar.gz$ cd redis-6.0.10$ make
当make的时候报错,提示make: *** [server.o] 错误 1 ,原因是因为当前默认的gcc版本太低,需要手动升级gcc。
升级GCC1234yum -y install centos-release-sclyum -y install devtoolset-9-*#临时启动gcc9scl enable devtoolset-9 bash
永久使用gcc9
1echo "source /opt/rh/devtoolset-9/enable" >>/etc/profile
redis启动和关闭1$ src/redis-server
后台启动设置,修改redis.conf,设置daemonize yes,重新启动。
1$ src/redis-server ...
TCP和UDP那些事儿
简介学习网络的时候都了解过tcp和udp的一些特点,比如tcp有三次握手四次挥手,tcp消息可靠;udp传递速度快,udp可能丢数据。但是如果在详细一点来说可能就没那么清楚了,在这里我就本着知其然知其所以然的目标尽量搞清楚这些概念和特点。
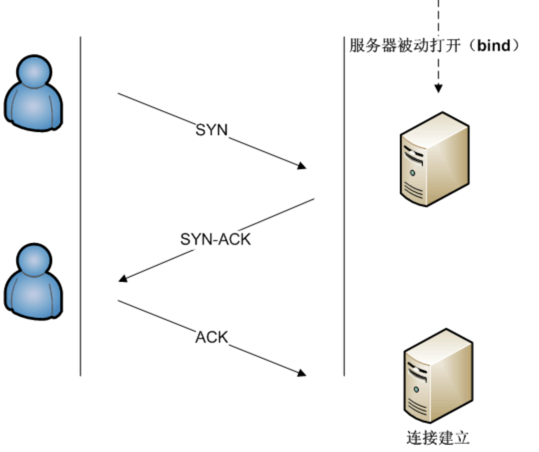
TCP首先我们先研究TCP:传输控制协议(英语:Transmission Control Protocol,缩写:TCP)是一种面向连接的、可靠的、基于字节流的传输层通信协议。在简化的计算机网络OSI模型中,它完成第四层传输层所指定的功能。TCP协议的运行可划分为三个阶段:连接创建(connection establishment)、数据传送(data transfer)和连接终止(connection termination)
连接创建(connection establishment)通常由一端(服务端)被被动打开一个套接字(socket)然后监听另一方(客户端)的连接,服务端执行了listen函数后,就在服务器创建两个队列:
SYN队列:存放完成了二次握手的结果。队列长度由listen函数的参数backlog指定。
ACCEPT队列:存放完成 ...

Mysql的一些问答
数据库相关问题数据库三范式
第一范式:确保每列的原子性,每列都是不可分割的最小数据单元
第二范式:在第一范式的基础上,要求每列都和主键相关
第三范式:在第二范式的基础上,要求其他列和主键是直接相关,而不是间接相关
分别说一下范式和反范式的优缺点1.范式化
优点:
减少苏局冗余
表中重复数据较少,更新操作比较快
范式化的表通常比范式化的表小
缺点:
在查询的时候通常需要很多关联,降低性能
增加了索引优化的难度
2.反范式化
优点:
可以减少表的关联
更好的进行索引优化
缺点:
数据重复冗余
对数据表的修改需要更多的成本
Mysql 数据库索引。B+ 树和 B 树的区别MySQL数据库索引和存储引擎有关,MyISAM和InnoDB只支持BTREE索引。MEMORY和HEAP支持HASH和BTREE索引
B+树和B树的区别
B+树非叶子节点只存储关键字和指向子节点的指针,而B树还存储了数据,在同样大小的情况下,B+树可以存储更多的关键字
B+树叶子节点存储了所有关键字和数据,并且多个节点用链表连接。可以快速支撑范围查找
B+树非叶子节点不存储数据,所以查询时间复杂度固定为 ...
ES和LogStash结合导入mysql数据
ES和LogStash结合导入mysql数据我们安装和启动好ES,学会了ES的用法后,现在要应用到我们实际的项目中,我们如何将现有的数据在ES中创建索引呢?下面将介绍两种方式,通过ES的api直接索引和通过LogStash组件进行索引。
通过ES的API进行索引本示例我们采用的Java语言开发,使用maven构建的工程,我们先把api相关依赖加入pom.xml
12345678910<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.12.1</version></dependency><dependency> <groupId>org.elasticsearch</groupId> <artifactId>e ...
Dubbo的负载均衡
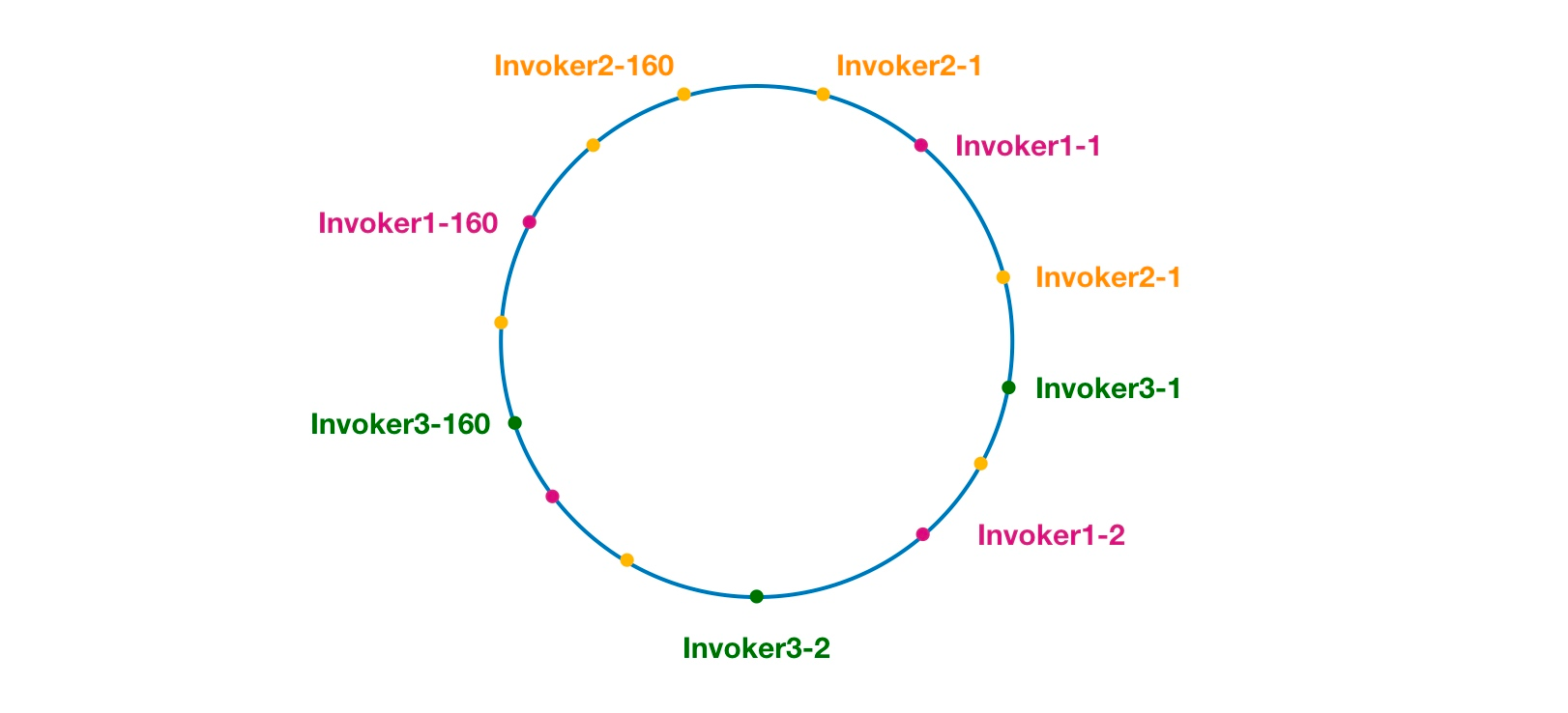
简介负载均衡其实就是一个同样的工作任务下,对具有同样一批工作能力的人根据不同策略进行分工的一个哲学问题。不过在程序中进行任务分配就比较单纯了,在Dubbo中分为这几个负载均衡策略:随机加权负载均衡、轮询加权负载均衡、最小活跃数负载均衡、一致性哈希负载均衡、还有在dubbo新版本中新增的最短响应负载均衡。比起Dubbo服务的导出,引用和调用过程的源码,负载均衡的源码更值得进行研究分析,因为这些算法不仅在Dubbo中出现,在apache,nginx都有类似的算法。下面我们会逐个进行分析。
源码分析分析负载均衡源码前,我们先了解下负载均衡的加载方式。在通过集群调用某个 inovker 之前,需要先选择出一个 invoker ,这时需要通过SPI加载一个负载均衡器,其源码如下:
12345678910// AbstractClusterInvokerprotected LoadBalance initLoadBalance(List<Invoker<T>> invokers, Invocation invocation) { // 通过配置 loadba ...
Dubbo的集群容错
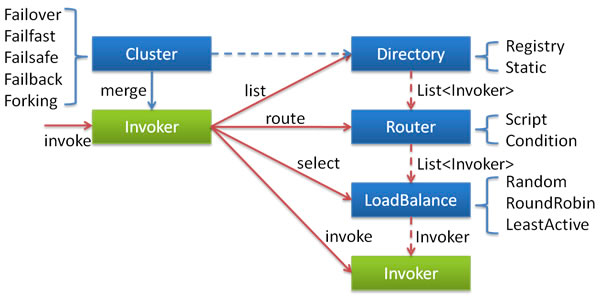
简介为了避免单点故障,现在的应用通常至少会部署在两台服务器上。对于一些负载比较高的服务,会部署更多的服务器。这样,在同一环境下的服务提供者数量会大于1。对于服务消费者来说,同一环境下出现了多个服务提供者。这时会出现一个问题,服务消费者需要决定选择哪个服务提供者进行调用。另外服务调用失败时的处理措施也是需要考虑的,是重试呢,还是抛出异常,亦或是只打印异常等。为了处理这些问题,Dubbo 定义了集群接口 Cluster 以及 Cluster Invoker。集群 Cluster 用途是将多个服务提供者合并为一个 Cluster Invoker,并将这个 Invoker 暴露给服务消费者。这样一来,服务消费者只需通过这个 Invoker 进行远程调用即可,至于具体调用哪个服务提供者,以及调用失败后如何处理等问题,现在都交给集群模块去处理。集群模块是服务提供者和服务消费者的中间层,为服务消费者屏蔽了服务提供者的情况,这样服务消费者就可以专心处理远程调用相关事宜。比如发请求,接受服务提供者返回的数据等。这就是集群的作用。
Dubbo 提供了多种集群实现,包含但不限于 Failover Clust ...